
Dynamic memory allocation
When does new memory get allocated in the kernel?
- New process gets created (fork())
- New program gets loaded into memory (execve())
- Process stack grows
- Process expands heap (malloc())
- Process “creates” (attaches to) shared memory segment (shmat())
- Map a file to memory (mmap())
Fragmentation
- External fragmentation
- Has enough memory, but the free memory are distributed and cannot be grouped to host a large block
- Internal fragmentation
- Use memory blocks
- Wasted space inside blocks
Allocation
Use free list to maintain free spaces.
Buddy system allocation:
Maintain multiple free lists, one for each power-of-2 size.
Allocation:
- Increase size of request to next power of 2*.
- Look up segment in free lists.
- If exists, allocate.
- If none exists, split next larger segment in half, put first half(the “buddy”) on free list, and return second half.
De-Allocation:
- Return segment to free list.
- Check if buddy is free. If so, coalesce.
Address spaces
All user programs think their memory spaces starts from 0x0, which are virtual addressing.
Paging
Naive relocation causes (external) fragmentation. Solve it by partition memory into equal-size portions.
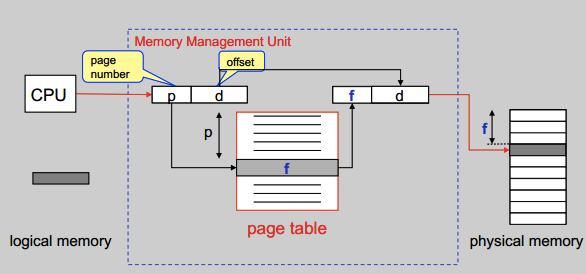
- Last frame may not be completely full.
- Average internal fragmentation per block is typically half frame size.
- Large frames cause more fragmentation.
- Small frames cause more overhead (page table size, disk I/O)
Page table
Issues:
- Page table must store one entry per page.
- Naive page table can become very large.
- 32-bit address space, 4kB pages, 4B entries
- 4MB for each process
Hierarchical (Multilevel) paging
Page the page table
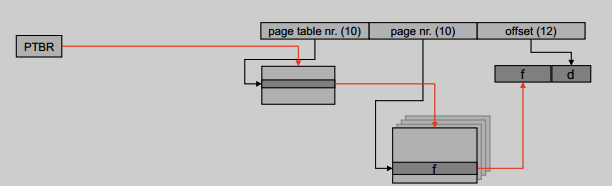
- Too many levels will increase the search time
- Needs to read memory more times
Inverted page table
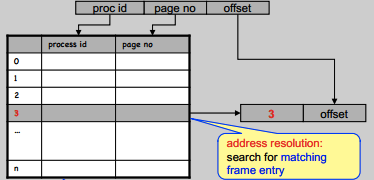
Pros:
- Scales with physical memory
- One table for whole system
Cons:
- Long search times for large physical memories
Hashed page table
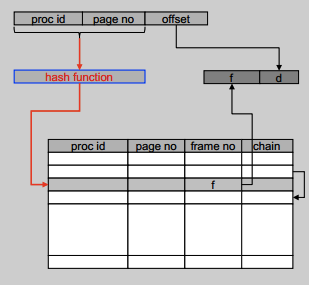
Pros:
- Scales with physical memory
- One table for whole system
Cons:
- How about collisions?
Translation Lookaside Buffers (TLB)
Use CPU to cache page number and frame number, allowing fast lookups.
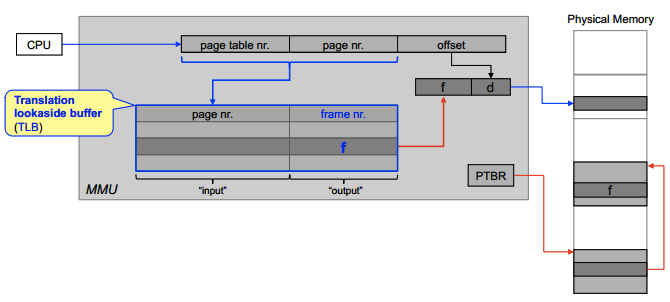
- Split virtual address, use page number.
- Look in the TLB to see if we find translation entry for page.
- If YES, use frame number.
- If NO, system must locate page entry in main-memory-resident page table, load it into TLB, and start again.
Note:
- One TLB per address space (process)
- Need to flush TLB for every process switch.
- One TLB for entire system
- Add address space ID in TLB entries
Software-managed TLBs, MIPS style
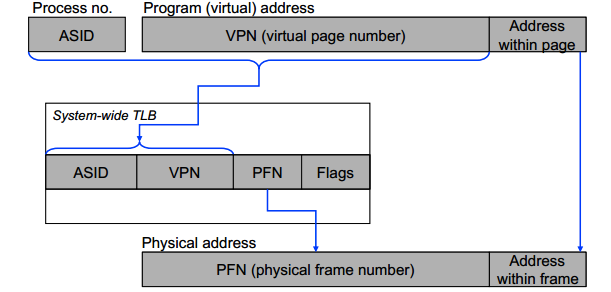
- Principle: Make do with as little hardware as possible.
- Apart from a register with the ASID, the MMU is just the TLB.
- The rest is all implemented in software!
- When TLB cannot translate an address, a special exception (TLB refill) is raised.
- Software then takes over.
TLB Refill Exception:
- Figure out if this virtual address is valid.
- If not, trap to handling of address errors.
- If address is valid, construct TLB entry.
- If TLB already full, select an entry to discard.
- Write the new entry into the TLB.
Segmentation
Users think of memory in terms of segments (data, code, stack, objects, …). Segmentation allows for efficient allocation and management of semantically-related data segments
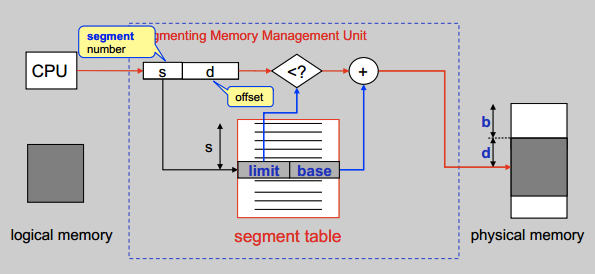
Pros:
- Data in a segment typically semantically
related - Protection can be associated with segments
- read/write protection
- range checks for arrays
- Data and code sharing
Cons:
- External fragmentation
Segmented paging
To elimimate external fragmentation.
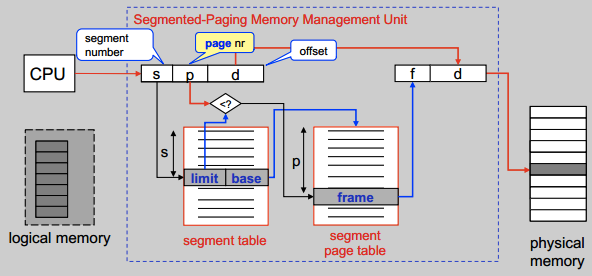
Paging on x86
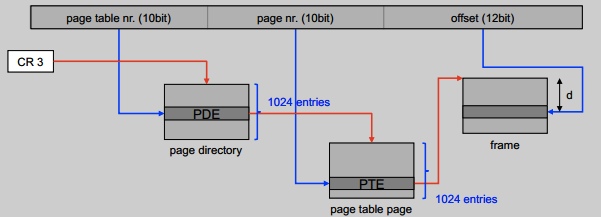
- CR0 controls whether to use paging
- CR3 loads the page directory table address (the last entry in this table points to the table itself)
- The page fault is Exception 14
err_codestores error code- offending address stored in CR2
- use bit set whenever page is referenced
- to identify recently-used pages
- dirty bit set whenever page is written
- to minimize I/O write operations
- don’t need to write while not dirty
- clear dirty bit when paging in
Page out
- We may swap out entire processes from memory to disk
- Can partially swap out memory of processes
- Processes never use all their memory at once
Page fault
Process of a page fault:
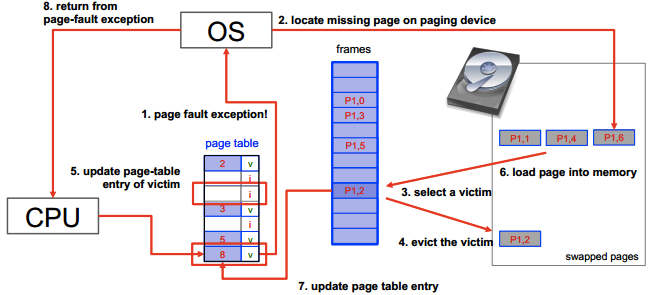
If all frames are used:
- Select a victim frame
- Update page table entry of victim to be invalid
- Page victim out
Policies
Locality of Reference: A program that references a location n at some point in time is likely to reference the same location n and locations in the immediate vicinity of n in the near future.
We can duplicate valid bit by a software-valid bit and have the kernel turn off the valid bit. The other bits can then be simulated in software.
Paging replacement policies:
- FIFO
- Replace the page that has been in memory for the longest period of time.
- Optimal
- Replace that page which will not be used for the longest period of time (in the future)
- LRU
- replace the page that has not been accessed for longest period of time (in the past)
- 2nd chance: Associate a use_bit with every frame in memory.
- Upon each reference, set use_bit to 1.
- Keep a pointer to next “victim candidate” page.
- To select victim: If current frame’s use bit is 0, select frame and increment pointer. Otherwise delete use bit and increment pointer.
- Enhanced 2nd chance
- Consider read/write activity of page: dirty bit
- Algorithm same as 2nd Chance Algorithm, except that we scan for pages with both use bit and dirty bit equal to 0.
- A dirty page is not selected until two full scans of the list later.
Each process requires a certain minimum set of pages to be resident in memory to run efficiently. Thrashing will happen when the basic needs of processes in a system cannot be satisfied.
Work set model
The memory management strategy follows two rules:
- Rule 1: At each reference, the current working set is determined and only those pages belonging to the working set are retained in memory.
- Rule 2: A program may run only if its entire current working set is in memory.
Problems:
- Difficulty in keeping track of working set.
- Estimation of appropriate window size.
- too small -> page out useful pages
- too big -> waste memory
Page buffering
- Victim frames are not overwritten directly, but are removed from page table of process, and put into:
- free frame list (clean frames)
- modified frame list (modified frames)
- Victims are picked from the free frame list in FIFO order.
- If referenced page is in free or modified list, simply reclaim it.
- Periodically (or when running out of free frames) write modified frame list to disk and add now clean frames to free list.
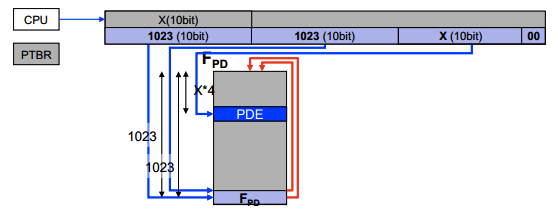
Recursive page table lookup
Idea is use the last entry in page directory table to point to the table itself.
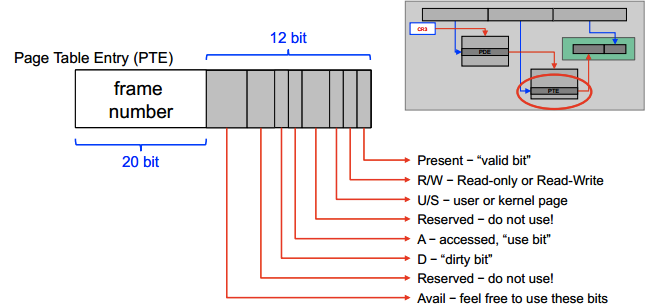
Access PTE:
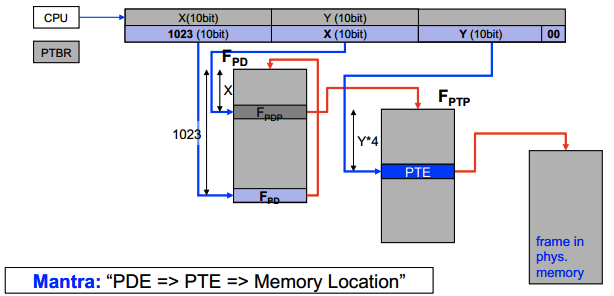
Access PDE:
Reference
This is my class notes while taking CSCE 611 at TAMU. Credit to the instructor Dr. Bettati.
