
evaluating a learning algorithm
deciding what to try next
debugging a learning algorithm
Unacceptably large errors in its predictions.
- get more training examples - fix high variance
- try smaller sets of features - fix high variance
- try getting addtional features - fix high bias
- try adding polynomial features - fix high bias
- try decreasing - fix high bias
- try increasing - fix high variance
diagnostic
A test that you can run to gain insight what is/isn’t working with a learning algorithm, and gain guidance as to how best to improve its performance.
Diagnostics can take time to implement, but doing so can be a very good use of time.
evaluating a hypothesis
training set: 70% (better randomly shuffled)
test set: 30%
training/testing procedure for linear regression
- learning parameter from training data (minimizing training error )
- compute test set error (cost function)
- get missclassification error (percentage of wrong predictions if classification problem)
model selection and training/validation/test sets
model selection
d: what degree of polynomial to choose for hypothesis
calculate the test set error for different degrees of polynomial cnd choose the one with minimum error
evaluating hypothesis
- training set: 60%
- cross validation set: 20%
- test set: 20%
Test parameters with different degree of polynomial on cross validation set. Estimate generalization error on the test set
bias vs. variance
diagnosing bias vs. variance
High bias: underfit. high training error and high validation error
High variance: overfit. low training error and much high validation error
regularization and bias/variance
regularization parameter
- large : high bias (underfit)
- small : high variance (overfit)
Define the cost function of training, validation and test sets without regularization terms.
- Create a list of
(i.e. ); - Create a set of models with different degrees or any other variants.
- Iterate through the s and for each go through all the models to learn some .
- Learn the parameter for the model selected, using with the selected.
- Compute the train error using the learned (computed with ) on the without regularization or .
- Compute the cross validation error using the learned (computed with ) on the without regularization or .
- Select the best combo that produces the lowest error on the cross validation set.
- Using the best combo and , apply it on to see if it has a good generalization of the problem.
learning curve
Plot or vs training set size m.
While m increases:
- increasing
- decreasing
While bias is high:
- The final errors for both training and validation will be high and similar
- Getting more training data will not help much
While variance is high:
- large gap between final errors for training and validation sets but approach each other while m increases
- getting more training data is likely to help
neural network
- small neural network: fewer parameters; more prone to underfitting; computationally cheaper
- large neural network: use regularization to address overfitting
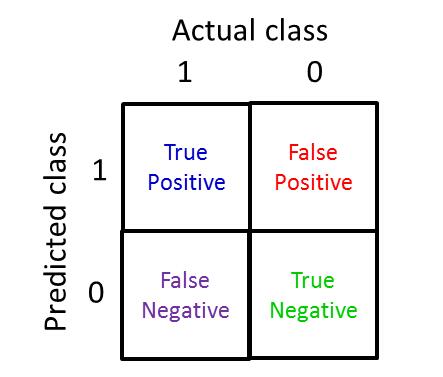
precision = (true positives)/(no. of predicted positive)
recall = (true positives)/(no. of actual positive)
use F1 score formula to evaluate algorithms:
