
models of neurons
Human Brain:
Stimulus Receptors Neural Net Effectors Response
- s per operation
- neurons and connections
-
per operation
- Synapses with associated weights : j to k denoted
- Summing function:
- Activation function:
- Bia : or
activation function
- threshold unit
- piece-wise linear
- sigmoid: logistic and
- signum function
- sign function
- hyperbolic tangent function
stochastic models
Instead of deterministic activation, stochastic activation can be done. Activated with a probability of firing .
A typical choice: . T is a pseudotemperature.
In computer simulation, use the rejection method.
definition of a neural network
- signals are passed between neurons over connection links
- each connection link has an associated weight, which typically multiplies the signal transmitted
- each neuron applies an activation function to its net input to determine its output signal
feedback
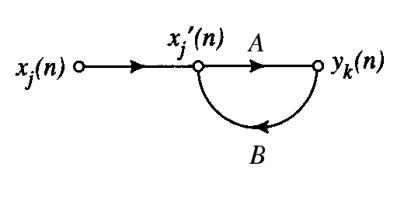
\[y_k(n) = A[x_j ‘(n)]\]
\[x_j ‘(n) = x_j(n) + B[y_k(n)]\]
So:
\[y_k(n) = \frac{A}{1-AB}[x_j(n)]\]
is called the closed-loop operator and is the open loop operator.
Substitute for and unit delay operator for .
\[\frac{A}{1-AB}=w(1-w z^{-1})^{-1}=w \sum_{l=0}^{\infty}w^l z^{-l}\]
So the output will be:
\[y_k(n)=w\sum_{l=0}^{\infty}w^l z^{-l}[x_j(n)]=\sum_{l=0}^{\infty}w^{l+1} x_j(n-l)\]
With a fixed , the output will be:
- : converge
- : linearly diverge
- : expontially diverge
network architectures
- single-layer feedforward: one input, one layer of computing units (output layer), acyclic connections
- multilayer feedforward: one input layer, one (or more) hidden layers, and one output layer
- recurrent: feedback loop exists
Layers can be fully connected or partially connected.
design of a neural network
- select architecture, and gather input samples and train using a learning algorithm
- test with data not seen before
- it’s a data-driven, unlike conventional programming
similarity measures
- reciprocal of Euclidean distance :
- dot product
When :
\[d^2(x_i,x_j) = 2-2 x_i^T x_j\]
- mean vector
- Mahalanobis distance:
- Covariance matrix is assumed to be the same:
