
Reference
Abstract
Zanzibar is a consistent, global authorization systems used by Google Calendar, Cloud, Drive, Maps, Photos and Youtube. It scales to billions of users, trillions of ACLs (access control list) and millions of QPS. It maintains 95th latency of less than 10 milliseconds and 5-9s availability over 3 years of production use.
Introduction
Zanzibar is a unified system that allows inter-application usages.
Goals for Zanzibar:
- Correctness
- Consistency
- Flexibility
- Support a rich set of access control policies.
- Low latency
- High availability
- Large scale
Zanzibar features:
- A simple data model and a powerful configuration language
- User can define arbitrary relations between users and objects, like owner.
- Support set-algebraic operators such as intersection and union.
- ACL: user U has relation R to object O.
- U can also be a user group, referring to another ACL.
- Commenter is also viewer.
- User group can contains other user groups. Nested groups may lead to long chain for ACL checks.
- An ACL check request may fan out to multiple servers.
- U can also be a user group, referring to another ACL.
- All ACLs are globally replicated to server large QPS quickly.
- Global consistency enabled by Spanner.
For low latency and high availability:
- Its consistency protocol allows the vast majority of requests to be served with locally replicated data, without requiring cross-region round trips.
- Handle hot spots by caching final and intermediate results, deduping simultaneous requests.
- Handle deeply nested sets by hedging request and optimizing computations.
Model, language and API
Relation tuples
In Zanzibar, ACLs are represented as relation tuples.
(tuple) ::= (object)#(relation)@(user)(object) ::= (namespace):(object_id)(user) ::= (user_id)|(userset)(userset) ::= (object)#(relation)
(userset) allows us to refer a group to support nested group membership.
Examples of tuples:
- doc:readme#owner@10
- group:eng#member@11
- doc:readme#viewer@group:eng#member
- Group eng’s members are viewers of readme.
Consistency model
“new enemy problem”, considering a scenario:
- Alice removes Bob from the ACL of a folder.
- Alice adds a new content into the folder.
Problems:
- Fail to preserve ordering of ACL changes.
- Wrong order will let Bob see the new content.
- Misapply old ACL to new content.
- If ACL check is evaluated on the old ACL, Bob will see the content.
Features Zanzibar provided to avoid such problems are as below. Both are enabled by Spanner (my note).
- External consistency
- Ensure casual ordering.
- Snapshot reads with bounded staleness
- Won’t see stale results.
Zookie:
- Zanzibar zookies are basically Spanner timestamp assigned to the ACL update.
- Write path
- When the content modification is about to be saved, the client requests a zookie for each content version.
- Via a content-change ACL check.
- Does not need to be in the same transaction as the content change. (Note: Why?)
- Via a content-change ACL check.
- The client stores the content change and the zookie in an atomic write.
- When the content modification is about to be saved, the client requests a zookie for each content version.
- Check path
- The client sends this zookie in subsequent ACL check requests to get fresh results compared with the update.
Advantages of using zookies:
- Most of checks use default staleness with already replicated data.
- Low latency.
- Free to choose even fresher snapshot.
- To avoid hot spots.
- High availability.
Namespace configuration
Namespace configuration specifies:
- Relations
- e.g., viewer, editor
- Storage parameters
- Sharding setting
- Encoding for object ID like string, integer.
Relation configs and user rewrites
Clients can define object-agnostic relationships via userset rewrite rules in relation configs. The userset rewrite rules are defined per relation. It can be used to express this relation with other relations. The expressions can be union, intersection and exclusion.
The userset rewrite rule specifies a function with an object ID as input and a userset expression tree as output. The leaf nodes of the tree can be:
_this- All users from tuples for
<object#relation>pair. - Including indirect ACLs by usersets from tuples.
- Default when no rules specified.
- All users from tuples for
computed_userset- Compute a new userset for the input object.
- e.g., viewer relation can refer to editor relation.
tuple_to_userset- Compute a tupleset from the input object; fetch relation tuples matching the tupleset; then compute a userset from every fetched relation tuple.
An example of relation config, expressing that viewer contains editor and viewer from parent folder; editor contains owner.
name: "doc"
relation { name: "owner" }
relation {
name: "editor"
userset_rewrite {
union {
child { _this {} }
child { computed_userset { relation: "owner" } }
}}}
relation {
name: "viewer"
userset_rewrite {
union {
child { _this {} }
child { computed_userset { relation: "editor" } }
child { tuple_to_userset {
tupleset { relation: "parent" }
computed_userset {
object: $TUPLE_USERSET_OBJECT # parent folder
relation: "viewer"
}}}
}}}
API
- Read
- A request specifies one or more tuplesets and zookie.
- tupleset:
- A single tuple key or all tuples with a a given object ID or userset in a namespace.
- Can be optionally constrained by a relation name.
- Response
- look up a specific membership entry;
- read all entries in an ACL or group;
- read all groups with a given user.
- Note Read doesn’t reflect userset rewrite rules, thus only retrieve direct users or objects.
- Use Expand to get effective ACLs.
- Write
- Can modify single relation tuple.
- Can also modify all tuples related to an object via a read-modify-write cycle.
- Steps:
- Read all relation tuples of an object, including a per-object lock tuple.
- Generate tuples to write or delete. Send the writes along with the lock tuple.
- If the lock tuple is not modified, commit. Otherwise, back to step 1.
- Steps:
- A write issues a content-change check against the latest snapshot.
- If authorized, Check will response with a zookie, to be sent back in the write response to the client.
- Watch
- Request: one or more namespaces, zookie representing the time starting to watch.
- Response: all tuple modification events in time order and a heartbeat zookie (representing the end time).
- Clients can use the heartbeat zookie to send a new request to resume watching.
- Can be used to maintain secondary indexes on client side.
- Check
- Request: a userset
<object#relation>, a putative user and optional zookie.
- Request: a userset
- Expand
- Get the effective userset given an
<object#relation>pair and an optional zookie. - Follow indirect references expressed through userset rewrite rules.
- Result: a userset tree
- Leaf nodes: user IDs or usersets pointing to other
<object#relation>pairs. - Intermediate nodes: expressions like union, intersection or exclusion.
- Leaf nodes: user IDs or usersets pointing to other
- Get the effective userset given an
Architecture and implementation
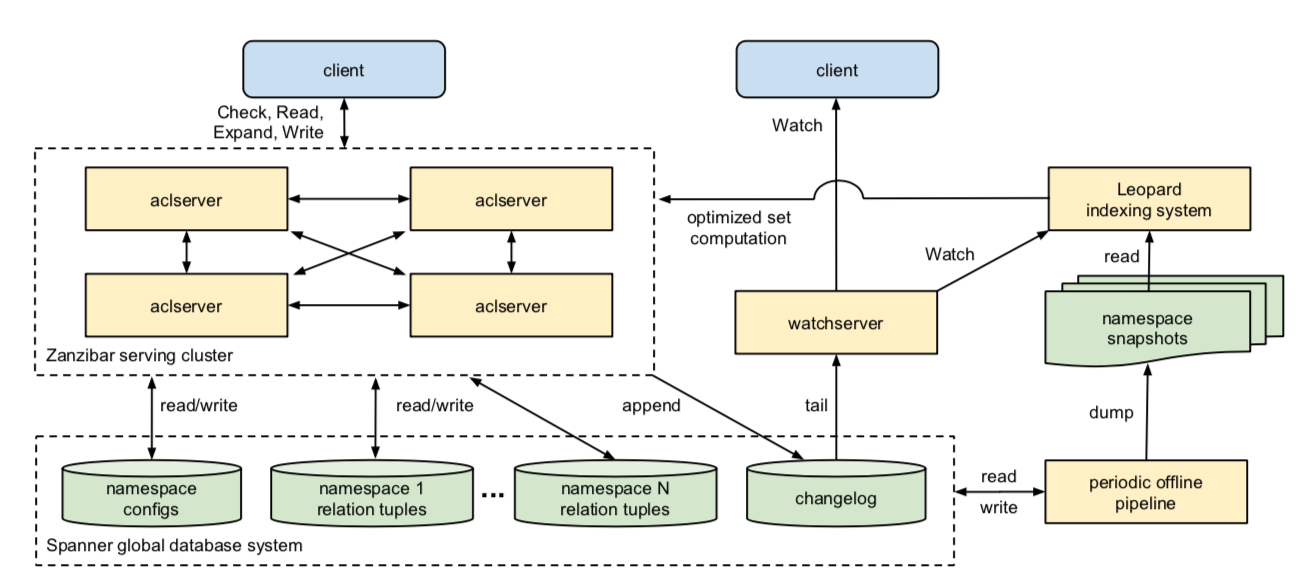
- aclservers
- Serve Check, Read, Expand, Write requests.
- Organized in clusters.
- The initial server may fan out work to other servers; other server may contact another server as well.
- The initial server gathers final result and sends it back to the client.
- Storage
- ACLs and metadata are stored in Spanner.
- One database per namespace.
- One database stores all namespace configurations.
- One changelog database shared across all namespaces.
- watchservers
- Serve Watch requests.
- Tail the changelog and serve a stream of changes.
- Offline pipelines
- e.g., dumps, garbage collection on old versions.
- Leopard indexing system
- Used to optimize operations on large and deeply nested sets.
Storage
Relation tuple storage:
- One database per namespace.
- Primary key to identify a row:
- shard ID, object ID, relation, user, commit timestamp.
- Shard ID
- Usually determined by object ID solely.
- If a namespace stores groups with very large numbers of members, shard ID can be computed from object ID and user.
- Usually determined by object ID solely.
Changelog:
- Primary key:
- changelog shard ID, timestamp, unique update ID.
- Shard is randomly selected for each write.
- Relation tuple and changelog are both updated in a single transaction.
- Use the Spanner server hosting changelog shard as the transaction manager.
- To minimize blocking of changelog reads on pending transactions.
- Note: Save the time for sending commit timestamp to non-coordinator participant leaders in 2PC.
- To minimize blocking of changelog reads on pending transactions.
Namespace config storage:
- Two tables:
- One stores the configs keyed by namespace IDs.
- The other is a changelog of config updates, keyed by commit timestamps.
- Zanzibar servers can load all configs upon startup and monitor the changelog to refresh configs.
Replication:
- Data is replicated to be close to clients.
- Dozens of locations around the world.
- 5 voting replicas in eastern and central US.
- in 3 metropolitan areas to isolate failures;
- within 25 ms of each other to allow Paxos transactions commit quickly.
Serving
Evaluation timestamp
Zanzibar always respects zookie if provided. Zanzibar also does statistics on out-of-zone reads probability. Default staleness bound will be updated to a safe value according to the result. Use default staleness for requests without zookies. The signal of whether it’s out-of-zone is sent back by Spanner.
Config consistency
Zanzibar chooses a single timestamp for the config to evaluate the same request on all servers. This timestamp is chosen from a range in which all timestamps are available to all servers.
- This range is maintained by a monitoring job.
- Each server load config changes continuously.
Check evaluation
Zanzibar converts check requests to boolean expressions. A simple example without userset rewrite rules:
- A check request fans out on all indirect ACLs or groups, recursively.
- Deep or write ACLs cases are optimized by Leopard indexing system.
- All leaf nodes of the boolean expression tree are evaluated concurrently.
- Eager cancellation: If the outcome of one node determines the result of a subtree, evaluations on other nodes are cancelled.
- Use pooling mechanism to group reads for the same ACL check to reduce the number of RPCs to Spanner.
Leopard indexing system
For namespaces with deeply nested groups or large number of child groups, they can be selected to use Leopard indexing system to reduce latency of checks. The idea is to flatten the group to group paths. A query to Leopard system is an expression of UNION, INTERSECTION or EXCLUSION of named sets (indexing tuples). Response is a set ordered by element ID up to a specified number of results.
An indexing tuple (T, s, e):
T: the set type.GROUP2GROUP(s) -> {e}: For a groups, return all directly or indirectly descendant groups{e}.MEMBER2GROUP(s) -> {e}: For a users, return all direct parent groups{e}.
s: set ID.e64-bit element ID.
Below is the check of user on group .
3 parts of Leopard system:
- A serving system for consistent and low-latency operations across sets
- Tuples are stored like a skip list, to perform operations (UNION, INTERSECTION) in .
- Index is sharded by element IDs.
- Note: Why? This way elements in the same set don’t stay together like a list.
- An offline periodic index building system
- Generate index shards from a snapshot of relation tuples and configs; and replicate.
- Respect the userset rewrite rules.
- An online layer for continuously updating the serving system as tuple changes occur
- Incrementally update indexes since the offline snapshot.
- An update is
(T, s, e, t, d).tis the timestamp of update.dis deletion maker.
- Implementation
- Rely on Zanzibar Watch API.
- A relation tuple update may trigger tens of thousands Leopard tuple events.
- Every Leopard server receives the Watch update stream and do the update with minimal impact on serving.
Handling hot spots
ACL reads and checks often lead to hot spots. 4 improvements:
- Distributed cache
- Distributed in a cluster of servers with consistent hashing.
- Compute forwarding key with object ID.
- Because a check on
<object#relation>often involves checks on other relation of the same object. These can be processed on the same server to save number of internal RPCs.
- Because a check on
- Compute forwarding key with object ID.
- Both caller and callee of the internal RPCs cache the results.
- Encode snapshot timestamp in cache key.
- Avoid using caches of old snapshots.
- Round up timestamps from the zookie.
- Ensure freshness.
- Most checks can share cached result at the same timestamp.
- Distributed in a cluster of servers with consistent hashing.
- Lock table
- To handle “cache stampede” problem.
- Concurrent requests create flash hot spots before the cache is populated with results.
- When receive concurrent requests of the same cache key, process one and block others until cache is ready.
- To handle “cache stampede” problem.
- Cache all relation tuples for hot check targets.
- Many users may issue current requests on the same
<object#relation>pair. - Cache all relation tuples for the pair.
- Trade read bandwidth for cacheability.
- Hot objects are determined dynamically by tracking the number of reads on each objects.
- Many users may issue current requests on the same
- Delay eager cancellation
- Eager cancellation: indirect ACL checks are often cancelled when parent check result is determined.
- Problem: Checks are cancelled before cache keys are populated; thus concurrent requests are blocked on the lock table entry.
- Note: The indirect ACL check is not cached. This request is the only one allowed to perform that check. Other concurrent requests are blocked on the check. Apparently, they need to wait longer if the check is cancelled.
- Improvement: delay eager cancellation when there are waiters on the corresponding lock table entry.
Performance isolation
- Requirement: If one client fails to provision enough resources for an unexpected usage pattern, other clients won’t be affected.
- Control
- CPU capacity
- Per client
- Throttling if exceeding the limit.
- Total number of outstanding RPCs for memory usage
- On Zanzibar server
- Per server
- Per client
- Number of concurrent reads
- On Spanner server
- Per (object, client)
- Per client
- CPU capacity
- Use different lock table keys for different clients.
- Prevent throttling on one client affecting others.
Tail latency mitigation
Zanzibar’s distributed processing needs to accommodate slow tasks.
- For calls to Spanner and Leopard servers
- Request hedging: Send the same request to multiple servers; use the first response and cancel others.
- Place at least 2 replicas of these backends in every geographical region.
- Practice: Send the first request; defer sending hedged requests until the initial one is known to be slow.
- Hedging delay threshold: dynamically calculate Nth percentile latency.
- thus only hedge a small fraction of total traffic;
- For requests to Zanzibar servers
- No hedging
- Hedging is effective only when requests have similar costs.
- Some Zanzibar checks are meant to be more time-consuming.
- Therefore, hedging will worsen latency by duplicate expensive requests.
- Rely on sharding and monitoring mechanisms.
- Detect and avoid slow servers.
- No hedging
Experience
Some statistics as of 2019:
- Namespace: 1,500.
- Relation tuples
- 2 trillion relation tuples, close to 100 terabytes.
- Number of tuples per namespace: 10 to 1 trillion.
- Median: 15,000.
- Replication location: more than 30.
- QPS: more than 10 million.
- Example of a peak event:
- Check: 4.2M.
- Read: 8.2M.
- Expand: 760K.
- Write: 25K.
- Example of a peak event:
- Server: more than 10,000.
- Organized in several dozen clusters.
- Number of servers per cluster: 100 to 1,000.
Requests
Two categories of requests are as below based on zookie oldness. The number of safe requests is about two orders of magnitude higher than that of recent requests. (QPS: 1.2M vs 13K as of 12/2018)
- Safe
- Zookies are more than 10 seconds old.
- Requests can be served locally.
- Recent
- Zookies are less than 10 seconds old.
- Requests need to be routed to leader replica, requiring inter-region round trips.
Latency
- Measurement: server side, live traffic.
- Check: 3ms at both safe and recent 50th.
- Write: 127ms at the 50th.
- Safe requests are much faster than recent ones.
Availability
- Define an available request: succeed in 5s for safe, 15s for recent requests.
- Measurement: replay some real requests with modified zookies and extended deadlines.
- 99.999% available for past 3 years.
Internals
- Delegated RPCs: Zanzibar servers contact other servers, internally.
- 22 million QPS at peak, half for reads, half for checks.
- Caching handles 200 million lookups per second at peak.
- 150M for checks, 50M for reads.
- Cache hit and RPCs saved by lock table
- Checks
- Delegate side: 10% cache hit, 12% by lock table.
- Delegator side: 2% cache hit, 3% by lock table.
- Save 500K RPCs per second.
- Reads
- Delegate side: 24% cache hit, 9% by lock table.
- Delegator side: less than 1% cache hit.
- For super-hot groups(0.1%), cache full set of members in advance.
- Checks
- Spanner side
- 20 million read RPCs to Spanner, thanks to caching and read request pooling.
- Number of rows per RPC: 1.5 at the median, 1,000 at the 99th.
- Latency: 0.5ms at the median, 2ms at the 95th.
- 1% of Spanner reads benefit from hedging.
- Leopard system
- 1.56M QPS at the median, 2.22M at the 99th.
- Latency: 150 microsec at the median, under 1ms at the 99th.
- Index incremental updates: 500 updates per second at the median, 1,500 at the 99th.
Lessons learned
- Flexibility to accommodate differences between clients.
- Access control patterns vary widely.
- Continuously add new features to support clients’ use cases.
- Freshness requirements are often but not always loose.
- Zookie ensures bounded staleness.
- Access control patterns vary widely.
- Performance optimization to support client behaviors observed in production.
- Request hedging is the key to reduce tail latency.
- Hot-spot mitigation is critical for high availability.
- Distributed cache, lock table, cache prefetching for hot items, delay eager cancellation.
- Performance isolation protects against misbehaving clients.
Related work
- Access control in multi-user OS
- Multics, UNIX, POSIX ACLs, VMS.
- Taos supports identity in distributed systems.
- Role-based access control
- Role is similar to relation in Zanzibar.
- Identity and Access Management (IAM)
- Amazon, Google, Microsoft’s cloud services.
- Unified ACL storage and RPC-based API.
- Google Cloud IAM is built on Zanzibar.
- TAO is a distributed storage for social graphs in Facebook.
- No external consistency.
- Chubby and Zookeeper don’t have features required to be Zanzibar’s storage.
Conclusion
- Unified access control data and logic
- Flexible data model and configuration
- External consistency
- Scalability, low latency and high availability
