
All chapters
- Reliable, Scalable, and Maintainable Applications
- Data Models and Query Languages
- Storage and Retrieval
- Encoding and Evolution
- Replication
- Partitioning
- Transactions
- Distributed System Troubles
- Consistency and Consensus
- Batch Processing
- Stream Processing
- The Future of Data Systems
Consistency and Consensus
- A distributed system can be fault-tolerant with the help of some algorithms and protocols.
- Problems can occur:
- Packets can be lost, reordered, duplicated or delayed.
- Clocks are approximate at best.
- Nodes can pause or crash at any time.
- Problems can occur:
- The best way of building fault-tolerant systems is to find some general-purpose abstractions with useful guarantees.
- Implement them once, and then let applications rely on those guarantees.
- Applications can ignore some problems of the distributed systems.
- Just like transactions.
- Consensus: one of the most important abstractions.
- Getting all of the nodes to agree on something.
- Systems can tolerant some faults; but impossible for some others.
Consistency guarantees
- Eventual consistency is pretty weak.
- If you stop writing to the database and wait for some unspecified length of time, then eventually all read requests will return the same value.
- Eventual consistency is hard because the behaviors are quite different from single-threaded program.
- Stronger consistency guarantees
- The systems with them may have worse performance, but easier to use correctly.
- Linearizability: one of the strongest consistency models in common use.
Linearizability
- Also known as atomic consistency, strong consistency, immediate consistency, or external consistency.
- The basic idea is to make a system appear as if there were only one copy of the data, and all operations on it are atomic; even there are actually multiple replicas.
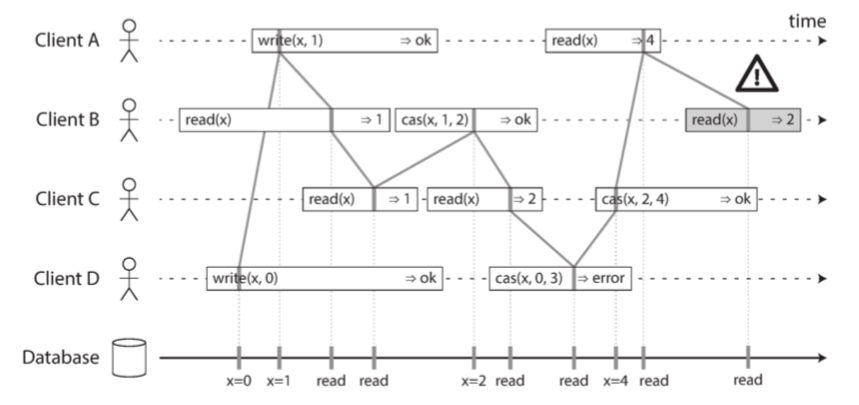
What makes a system linearizable?
- An operation is not instantly done, but a duration of time.
- If one client read the new value, others cannot read old value.
- B’s final read is not linearizable. (After A read the new value.)
- It’s OK that D’s CAS operation returns error.
- It is possible (though computationally expensive) to test whether a system’s behavior is linearizable by recording the timings of all requests and responses, and checking whether they can be arranged into a valid sequential order.
- Serializable snapshot isolation is not linearizable.
- Read from a snapshot.
Relying on Linearizability
Circumstances where linearizability is useful:
- Locking and leader election
- To elect a leader, every node tries to acquire the lock.
- The lock must be linearizable: all nodes must agree which node owns the lock.
- Distributed lock implementations: ZooKeeper, etcd, Curator.
- Constraints and uniqueness guarantees
- Require there to be a single up-to-date value that all nodes agree on.
- e.g., a username must be unique; enforce this constraint as the data is written.
- e.g., a bank balance never goes negative.
- Sometimes, we can treat constraint loosely, thus don’t need linearizability.
- e.g., overbooked flight
- Cross-channel timing dependencies
- Race conditions due to different communication channels between two services.
- Different versions of data from two channels.
Implementing linearizable systems
A single-copy system is indeed linearizable but not fault tolerant. We use replication to make a system fault tolerant.
- Single-leader replication (potentially linearizable)
- All writes goes to leader.
- Potentially linearizable if we read from the leader or synchronously updated followers.
- But not for all implementations, due to snapshot isolation or concurrency bugs.
- Consensus algorithms (linearizable)
- Contain measures to prevent split brain and stale replicas.
- e.g., ZooKeeper, etcd
- Multi-leader replication (not linearizable)
- Conflicting writes that requires resolution.
- Leaderless replication (probably not linearizable)
- Dynamo-style
- Possible to have non-linearizable behaviors
- Causes: Last write wins based on clocks (clock skew); sloppy quorums, etc.
- Clock timestamps cannot be guaranteed to be consistent with actual event ordering due to clock skew.
- Causes: Last write wins based on clocks (clock skew); sloppy quorums, etc.
- Can be linearizable with some performance reduced.
- A reader must perform read repair synchronously, before returning results to application.
- A writer must read the latest state of a quorum of nodes before sending its writes.
- Cassandra does wait for read repair to complete on quorum reads, but it loses linearizability if there are multiple concurrent writes to the same key, due to its use of last-write-wins conflict resolution.
- Riak doesn’t do this.
- Linearizable CAS operations here cannot be implemented; it requires a consensus algorithm.
The cost of linearizability
- Multi-leader database
- If there are a partition between datacenters, each datacenter can continue operating normally. They can serve writes and linearizable reads individually. Writes from one datacenter are replicated to the other asynchronously.
- The writes are simply queued up and exchanged while the network is restored.
- If there are a partition between datacenters, each datacenter can continue operating normally. They can serve writes and linearizable reads individually. Writes from one datacenter are replicated to the other asynchronously.
- Single-leader database
- If partition happens and clients are associated with the follower datacenter, writes and linearizable reads can not be served.
- Only leader can served these requests.
- If partition happens and clients are associated with the follower datacenter, writes and linearizable reads can not be served.
CAP: either Consistent or Available when Partitioned. It has little practical value today.
- Consistency/Linearizability
- Availability
- Partition tolerance
Few systems implement linearizability, because of performance, not much of fault tolerance. With linearizability implemented, the response time of read and write requests is at least proportional to the uncertainty of delays in the network.
Ordering guarantees
Ordering is an important theme in distributed systems.
- The main purpose of the leader in single-leader replication is to determine the order of writes in the replication log.
- The order in which followers apply those writes.
- Serializability ensures transactions are executed in some sequential order.
- Timestamps and clocks attempt to introduce order into a disorderly world.
Ordering and causality
Causality imposes an ordering on events: cause comes before effect; a message is sent before that message is received; the question comes before the answer. Ordering can help preserve causality. If a system obeys the ordering imposed by causality, we say that it is causally consistent. (Snapshot isolation is one example)
- Total order: all items are comparable.
- e.g., natural numbers
- Partial order: sometimes comparable, otherwise incomparable
- e.g., mathematical sets
Two database consistency models:
- Linearizability
- Total order of operations
- No concurrent operations
- We can always tell which happens first.
- Stronger than causality
- Causality
- Partial order
- Concurrent operations exist.
- Branches and merges, like Git
- We know the order on a single line of history; but cannot compare different branches.
- Causal consistency is the strongest possible consistency model that does not slow down due to network delays, and remains available in the face of network failures.
Determine the causal dependencies:
- If one operation happened before another, then they must be processed in that order on every replica.
- When a replica processes an operation, it must ensure that all causally preceding operations (all operations that happened before) have already been processed.
- Partial order: concurrent operations may be processed in any order.
- Determine which operation happened before which other operation: Use version vectors to track causal dependencies across the entire database.
- Pass the version numbers of data read along with the write to database, thus to check causality.
Sequence number ordering
We can use timestamps (from either time-of-day or logical clock) to order events. Timestamps implies total order; it can be consistent with causality. Such strategy can be performed with single-leader replication.
But if we don’t have a single leader, we can generate the sequence numbers for operations with 3 options:
- Each node can generate its own independent set of sequence numbers. For example, if you have two nodes, one node can generate only odd numbers and the other only even numbers.
- Problem: Each node may process a different number of operations per second. Thus, if one node generates even numbers and the other generates odd numbers, the counter for even numbers may lag behind the counter for odd numbers, or vice versa. If you have an odd-numbered operation and an even-numbered operation, you cannot accurately tell which one causally happened first.
- You can attach a timestamp from a time-of-day clock (physical clock) to each operation.
- Problem: Timestamps from physical clocks are subject to clock skew, which can make them inconsistent with causality.
- You can pre-allocate blocks of sequence numbers. For example, node A might claim the block of sequence numbers from 1 to 1,000, and node B might claim 1001 to 2000.
- Problem: One operation may be given a sequence number in the range from 1,001 to 2,000, and a causally later operation may be given a number in the range from 1 to 1,000. Here, again, the sequence number is inconsistent with causality.
Lamport timestamps: a simple method for generating sequence numbers that is consistent with causality.
- Each node has a unique identifier and keeps a counter of the number of operations it has processed.
- The timestamp is
(counter, node ID). - Total order
- Compare counter first.
- If the same counter, compare node ID.
- Every node and every client keeps track of the maximum counter value it has seen so far, and includes that maximum (+1) on every request. When a node receives a request or response with a maximum counter value greater than its own counter value, it immediately increases its own counter to that maximum.
Total ordering with timestamps may be not sufficient. Say we want to ensure the username is unique. We must prevent the second try (from the two concurrent writes) happening instead of finding it’s invalid after two writes.
The problem here is that the total order of operations only emerges after you have collected all of the operations. If another node has generated some operations, but you don’t yet know what they are, you cannot construct the final ordering of operations: the unknown operations from the other node may need to be inserted at various positions in the total order.
We need to know when the total ordering is finalized to make sure no other nodes can insert a claim for the same username ahead of your operation in total order. This idea of knowing when your total order is finalized is captured in the topic of total order broadcast.
Total order broadcast
Single-leader replication determines a total order of operations by sequencing all operations on the leader node. Total order broadcast is trying to do the similar thing in distributed systems (A single leader cannot handle the large throughput; failover if the leader fails).
Basically, Total order broadcast is a protocol for exchanging messages between nodes. It requires two safety properties:
- Reliable delivery
- No messages are lost: if a message is delivered to one node, it is delivered to all nodes.
- Network may be interrupted, but messages will be delivered once it’s restored and arrive in correct order.
- Totally ordered delivery
- Messages are delivered to every node in the same order.
Using total order broadcast:
- Used by consensus services such as ZooKeeper and etcd.
- Can be used for database replication.
- Every write is a message.
- Every replica processes messages in the same order.
- Serializable transactions
- Every transaction to be executed as a stored procedure is a message.
- Used to create logs.
- Appending a log is a message.
- Used to implement a lock service that provides fencing tokens.
- Every request to acquire the lock is appended as a message to the log, and all messages are sequentially numbered in the order they appear in the log.
- The sequence number can be served as fencing token. (
zxidin ZooKeeper)
- Messages cannot be inserted into previously processed order.
- Stronger than timestamp ordering
Implement linearizable storage using total order broadcast:
- Linearizability and total order broadcast are different.
- Total order broadcast is asynchronous: messages are guaranteed to be delivered reliably in a fixed order, but there is no guarantee about when a message will be delivered (so one recipient may lag behind the others).
- Linearizability is a recency guarantee: a read is guaranteed to see the latest value written.
- Build linearizable storage on top of total order broadcast.
- e.g., make sure usernames are unique.
- Called sequential consistency or timeline consistency.
- A linearizable system with several name registers and an atomic CAS operation.
- CAS: Only set the username when the username for this account is
null.
- CAS: Only set the username when the username for this account is
- Steps
- 1, Append a message to the log, tentatively indicating the username you want to claim.
- 2, Read the log, and wait for the message you appended to be delivered back to you.
- 3, Check for any messages claiming the username that you want.
- Success: If the first message for your desired username is your own message, commit the claim.
- It doesn’t guarantee linearizable reads since data can be stale.
- To guarantee it: If the log allows you to fetch the position of the latest log message in a linearizable way, you can query that position, wait for all entries up to that position to be delivered to you, and then perform the read. (This is the idea behind ZooKeeper’s
sync()operation)
- To guarantee it: If the log allows you to fetch the position of the latest log message in a linearizable way, you can query that position, wait for all entries up to that position to be delivered to you, and then perform the read. (This is the idea behind ZooKeeper’s
Implementing total order broadcast using linearizable storage:
- Assume we have a linearizable register that stores an integer and that has an atomic increment-and-get operation.
- For every message you want to send through total order broadcast, you increment-and-get the linearizable integer, and then attach the value you got from the register as a sequence number to the message. You can then send the message to all nodes (resending any lost messages), and the recipients will deliver the messages consecutively by sequence number.
- Hard to implement linearizable integer with an atomic IAG operation, finally end up with a consensus algorithm.
- A linearizable compare-and-set (or increment-and-get) register and total order broadcast are both equivalent to consensus.
Distributed transactions and consensus
Consensus is to get several nodes to agree on something. It sounds easy but actually subtle.
Situations where we need consensus:
- Leader election
- Avoid bad failover, resulting in a split brain.
- Atomic commit
- A transaction must be committed on all nodes or aborted/rolled back.
FLP result (Fischer, Lynch, and Paterson) proves that here is no algorithm that is always able to reach consensus if there is a risk that a node may crash. It’s for asynchronous system model where a deterministic algorithm cannot use any clocks or timeouts. If the algorithm is allowed to use timeouts, or some other way of identifying suspected crashed nodes (even if the suspicion is sometimes wrong), then consensus becomes solvable. Even just allowing the algorithm to use random numbers is sufficient to get around the impossibility result.
Atomic commit and two-phase commit (2PC)
Atomicity ensures that a transaction either committed successfully or be aborted. No half-finished state. It’s especially important for multi-object transactions and database with secondary indexes. Because secondary indexes are separate data structures from the primary data. We need to make sure the secondary index stays consistent with the primary data.
For atomic commit,
- On a single node,
- Atomicity is commonly implemented by the storage engine.
- Steps:
- Write data: Database makes the transaction’s writes durable.
- Typically in a write ahead log.
- Write commit record: Append a commit record to the log on disk.
- Write data: Database makes the transaction’s writes durable.
- The transaction is committed once the commit record is written successfully.
- On multiple nodes (maybe a partitioned database),
- Operations may succeed on some nodes and fail on others.
- A node can only commit if it know all operations has succeeded.
- A transaction commit must be irrevocable.
- You are not allowed to change your mind and retroactively abort a transaction after it has been committed.
Two-phase commit: an algorithm for achieving atomic transaction commit across multiple nodes — i.e., to ensure that either all nodes commit or all nodes abort.
- Use a coordinator (or transaction manager) to manage.
- When the application is ready to commit:
- Phase 1: Coordinator sends a prepare request to each of the nodes, asking whether they are prepared to commit.
- Phase 2:
- If all nodes reply “yes”, coordinator sends out a commit request and the commit actually takes place.
- If any replies “no”, coordinator sends an abort request to all nodes.
Detailed process of a commit:
- Application requests a unique transaction ID from the coordinator.
- The application begins a single-node transaction on each of the participants, and attaches the globally unique transaction ID to the single-node transaction.
- If anything wrong at this step, the coordinator or nodes can abort.
- Coordinator sends the prepare request with the transaction ID, when the application is ready to commit.
- When receiving the prepare request, a node makes sure that it can definitely commit the transaction under all circumstances. (A promise) Send the response to the coordinator.
- Writing all transaction data to disk.
- Checking for any conflicts or constraint violations.
- When the coordinator has received responses to all prepare requests, it makes a definitive decision on whether to commit or abort.
- The coordinator must write that decision to its transaction log on disk so that it knows which way it decided in case it subsequently crashes. (A promise) This is called the commit point.
- Once the coordinator’s decision has been written to disk, the commit or abort request is sent to all participants. If this request fails or times out, the coordinator must retry forever until it succeeds.
Coordinator failure:
- If the coordinator fails after sending prepare requests, it may not abort transaction on nodes. Node itself cannot abort its sub-transaction too. It ends up with uncertain/in-doubt state in nodes.
- When it happens, 2PC algorithm will wait the coordinator to recover. Once recovered, coordinator can read the transaction log to determine the status of all uncertain transactions and take actions.
- Abort all transactions whose TXID are not in the coordinator’s transaction log.
- 2PC is a blocking atomic commit protocol since it can become stuck waiting for the coordinator to recover.
- In-doubt transactions hold row-level locks of related data on participants.
- These locks can only be released if the transaction is committed or aborted.
- No other transactions can modify these rows.
- Orphaned in-doubt transactions do occur due to lost or corrupted transaction log.
- Only way to solve it is to manually decide whether to commit or roll back the transactions on involved participants.
- Heuristic decisions: allowing a participant to unilaterally decide to abort or commit an in-doubt transaction without a definitive decision from the coordinator.
- But violate the 2PC.
Three-phase commit
- 3PC assumes a network with bounded delay and nodes with bounded response times.
- Most systems has unbounded network delay and process pauses.
- Non-blocking atomic commit requires a perfect failure detector.
- In a network with unbounded delay a timeout is not a reliable failure detector.
Distributed transactions in practice
- Distributed transactions provide an important safety guarantee.
- Problems: killing performance, promising more than they can deliver.
- 10 times slower than single-node ones in MySQL.
- Two different types of distributed transactions
- Database-internal distributed transactions
- All nodes run the same database software.
- Heterogeneous distributed transactions
- The nodes are two or more different technologies.
- Require all nodes use the same atomic commit protocol.
- e.g., Email server doesn’t support 2PC, thus not qualified as a part.
- More challenging
- e.g., A transaction can include a message delivery of a message queue and a database transaction (side effects of the message).
- Ensure the message is processed only once even with retries.
- Database-internal distributed transactions
XA transactions
- X/Open XA (short for eXtended Architecture) is a standard for implementing two-phase commit across heterogeneous technologies.
- Supported by
- Many traditional relational databases (including PostgreSQL, MySQL, DB2, SQL Server, and Oracle).
- Message brokers (including ActiveMQ, HornetQ, MSMQ, and IBM MQ).
- XA is a C API for interfacing with a transaction coordinator.
- In other languages too, such as Java.
- XA assumes that your application uses a network driver or client library to communicate with the participant databases or messaging services.
- The transaction coordinator implements the XA API, within the same process of the application.
Limitations of distributed transactions
- Coordinator: a kind of database storing transaction outcomes.
- Single point of failure if not replicated.
- Adding coordinator with logs will break the stateless model of many server-side applications.
- Stateless model: all persistent state stored in a database, thus application server can be added or removed at will.
- Since XA needs to be compatible with a wide range of data systems, it is necessarily a lowest common denominator.
- It cannot detect deadlocks across different systems, since that would require a standardized protocol for systems to exchange information on the locks that each transaction is waiting for.
- It does not work with SSI, since that would require a protocol for identifying conflicts across different systems.
- Distributed transactions thus have a tendency of amplifying failures.
- If any part of the system is broken, the transaction also fails.
Fault-tolerant consensus
Consensus problem: one or more nodes may propose values, and the consensus algorithm decides on one of those values.
Some problems that are reducible to consensus:
- Linearizable CAS registers
- Atomic transaction commit
- Total order broadcast
- Locks and leases
- Membership/coordination service
- Uniqueness constraint
A consensus algorithm must satisfy following properties. First 3 are safety; termination is liveness.
- Uniform agreement
- No two nodes decide differently.
- Integrity
- No node decides twice.
- Validity
- If a node decides value
v, thenvwas proposed by some node.
- If a node decides value
- Termination
- Every node that does not crash eventually decides some value.
- Important if we have node failures.
- The system model of consensus assumes that when a node “crashes”, it suddenly disappears and never comes back.
- 2PC doesn’t work here.
- The system model of consensus assumes that when a node “crashes”, it suddenly disappears and never comes back.
- At least a majority of nodes are required to be good to satisfy termination.
- But most implementations ensure the first 3 safety properties even if a majority of nodes fail or there is a severe network problem.
- The problems cannot corrupt the consensus system by causing it to make invalid decisions.
Consensus algorithms:
- Best-known fault-tolerant consensus algorithms
- Viewstamped replication (VSR)
- Paxos
- Raft
- Zab
- Algorithms decide on a sequence of values. (total order broadcast)
- Total order broadcast is equivalent to repeated rounds of consensus.
- Each consensus decision is one message delivery.
- Total order broadcast
- Uniform agreement
- All nodes decide to deliver the same messages in the same order.
- Integrity
- Messages are not duplicated.
- Validity
- Messages are not corrupted and not made up.
- Termination
- Messages are not lost.
- VSR, Raft and Zab implement this directly.
- Known as Multi-Paxos in Paxos.
- Uniform agreement
Leader election:
- Epoch number: a monotonically increasing total ordered number.
- Ballot number in Paxos, view number in Viewstamped Replication, and term number in Raft
- Every time the current leader is thought to be dead, a vote is started among the nodes to elect a new leader.
- The leader with higher epoch number wins over leaders with smaller number.
- For a leader, to make a decision:
- Need to make sure it is the latest leader.
- Collect votes from a quorum of nodes.
- Propose, collect feedback.
- A node votes a proposal only if it doesn’t know a higher leader.
- Key is that the quorums for the most recent leader election and for a leader’s proposal must overlap.
- Thus the proposing leader knows there is not recent leader election.
- Collect votes from a quorum of nodes.
- Need to make sure it is the latest leader.
Limitations:
- Voting on proposals and then deciding is a kind of synchronous replication.
- Databases usually use asynchronous settings for better performance; but risk on losing committed data on failover.
- Require a strict majority to operate.
- Most consensus algorithms assume a fixed set of nodes that participate in voting, which means that you can’t just add or remove nodes in the cluster.
- Dynamic membership extensions exist, but they are harder to understand.
- Consensus systems generally rely on timeouts to detect failed nodes.
- Nodes may incorrectly think the leader is dead.
- Falsy detections due to environments with highly variable network delays, especially geographically distributed systems.
- Sensible to unreliable networks.
Membership and coordination services
ZooKeeper and etcd are distributed k-v stores or coordination and configuration services storing small amount of important data across nodes in a distributed systems. These data are replicated using a fault-tolerant total order broadcast algorithm, thus all such data on nodes are consistent.
Zookeeper features:
- Linearizable atomic operations
- Require consensus.
- We can implement locks using an atomic CAS operation.
- Distributed locks are often implemented as a lease, which has an expiry time.
- Total ordering of operations
- Monotonically increasing
zxidas fencing token - Fencing token increases every time a lock is acquired.
- Monotonically increasing
- Failure detection
- Clients maintain a long-lived session on ZooKeeper servers, and the client and server periodically exchange heartbeats to check that the other node is still alive.
- Change notifications
- Clients can subscribe notifications to know joins/failures of other nodes.
Allocating work to nodes:
- Examples
- Leader election
- Job scheduler
- Decide which partition to server the request
- How to re-balance load when node joins/fails
- API built on ZooKeeper
- e.g., Apache Curator
- ZooKeeper runs on a fixed number of nodes (usually three or five) and performs its majority votes among those nodes while supporting a potentially large number (like thousands) of clients.
- Normally, the kind of data managed by ZooKeeper is quite slow-changing.
- e.g., The node running on 10.1.1.23 is the leader for partition 7.
- Not intended for storing runtime state of applications.
- Other tools like Apache BookKeeper.
Service discovery:
- To find out which IP address you need to connect to in order to reach a particular service.
- Configure the services such that when they start up they register their network endpoints in a service registry, where they can then be found by other services.
- DNS is useful but maybe stale and not linearizable.
- Does not require consensus.
- But more important that DNS is reliably available and robust to network interruptions.
- Can have some read-only caching replicas.
- Do not participate in voting of consensus.
- Log decisions of consensus algorithm.
- Serve read requests that do not require linearizability.
- Like who the leader is.
- Tools: ZooKeeper, etcd, Consul
A membership service determines which nodes are currently active and live members of a cluster. Due to unbounded network delays it’s not possible to reliably detect whether another node has failed. However, if you couple failure detection with consensus, nodes can come to an agreement about which nodes should be considered alive or not. Although a node may be incorrectly declared dead, it’s very useful for a system to have an agreement.
