
Reference
Introduction
Spanner is Google’s scalable, globally-distributed database. It shards data across many sets of Paxos state machines spread all over the world. Data is also replicated to support availability and geographic locality. To balance load or respond to failures, data can be re-sharded or migrated automatically according to data or server changes.
Most applications favor lower latency over higher availability, thus they use less datacenters for replication (3 to 5 across US), as long as they can survive 1 to 2 datacenter failures.
Comparison with other Google databases:
- Bigtable
- Difficult to use for some applications with complex, evolving schemas.
- Doesn’t provide strong consistency in the presence of wide-area replication.
- Megastore
- Good to have semi-relational data model.
- Support synchronous replication.
- Write throughput is relatively poor.
- Spanner
- Schematized semi-relational tables.
- Data is versioned and each version is timestamped with its commit time.
- Applications can read data at old timestamps.
- Garbage collections on old versions.
- Support general transactions.
- Support SQL-based queries.
Other features:
- Replication configurations for data can be dynamically controlled at a fine grain by applications.
- Which datacenter contains which data.
- How far data is from users.
- How far replicas are from each other.
- How many replicas.
- Data can be dynamically and transparently moved across datacenters to balance.
- Provide externally consistent reads and writes (linearizability).
- Provide globally-consistent reads across database at a timestamp.
These features are enabled by the fact that Spanner assigns globally-meaningful commit timestamps to distributed transactions, which reflect serialization order. If a transaction T1 commits before another transaction T2, then T1’s timestamp is smaller than T2’s.
TrueTime API:
The key enabler is TrueTime API. It directly expose clock uncertainty (generally less than 10ms). If uncertainty is large, Spanner slows down to wait out that uncertainty. The API implementation is using both GPS and atomic clocks.
Note: Example of how the TrueTime helps. Say we have 2 nodes A and B and 2 transaction T1 and T2.
Without TrueTime:
- At true time 10, A time 15, A updates A’s value from “A1” to “A2”, T1 committed at timestamp 15.
- At true time 15, B time 10, B updates B’s value from “B1” to “B2”, T2 committed at timestamp 10.
- Client performs a read with timestamp 10, It sees “A1” and “B2”, which is inconsistent with actual true time order.
With TrueTime, uncertainty 15 (larger than the difference of server timestamps):
- At true time 10, A time 15, A updates A’s value from “A1” to “A2”, T1 committed at timestamp 15.
- Wait uncertainty 15, true time is 25.
- Now true time 15 (which is T1’s timestamp) has passed.
- At true time 30, B time 25, B updates B’s value from “B1” to “B2”, T2 committed at timestamp 25.
- Client performs a read with timestamp 25, It sees “A2” and “B2”.
Note: Vector clock is another method solving this. Now a clock is represented as a vector <ts1, ts2, ..., tsn>. n is the number of nodes. In case of two nodes, the clock vector is <ts1, ts2>. The following example shows that the clock vectors reflect actual serialization order as well. However, we may have too many nodes in Spanner group, thus cost could be huge to store, write and transport the vectors. We can understand why it’s not used in Spanner. This vector clock may sound similar to Lamport timestamp, but better. Lamport timestamp can enforce total order, but cannot describe concurrent events well. Vector clock records timestamps on all nodes to represent such causality.
- At true time 10, A time 15, A updates A’s value from “A1” to “A2”, T1 committed at timestamp
<15, 0>. - This timestamp is broadcasted to other nodes, B updated its timestamp to
<15, x>. - At true time 15, B time 10, B updates B’s value from “B1” to “B2”, committed at timestamp
<15, 10>.
Implementation
A Spanner deployment is called universe, which can be global. Currently, there are 3 universes: test/playground, dev/prod and prod-only universes.
Spanner is organized as a set of zones. Zone is the unit of administrative deployment; location across which data can be replicated; unit of physical isolation. For physical isolation, one datacenter may have multiple zones as different applications’ data must be partitioned across different sets of servers in the same datacenter. Zone can be added or removed, as datacenters added or turned off.
The Spanner servers are organized as below.
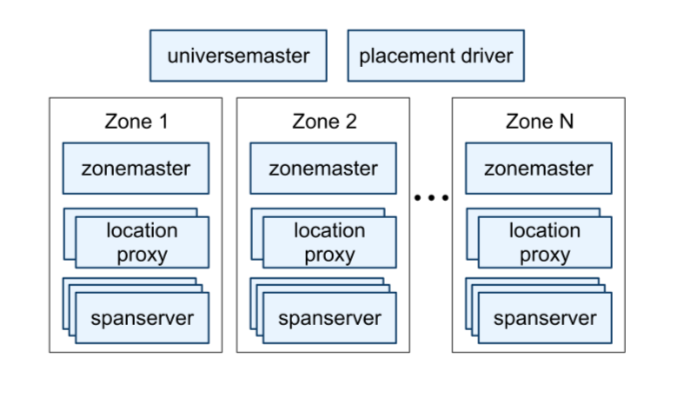
- Universe level
- universemaster
- A console displaying status information about all zones for debugging.
- placement driver
- Handle automated data movement across zones in minutes.
- Communicate with spanservers periodically.
- universemaster
- Zone level
- zonemaster
- Assign data to spanservers.
- One per zone.
- location proxies
- Used by clients to locate spanservers to serve their data.
- spanservers
- Serve data to clients.
- 100 to several thousand per zone.
- zonemaster
Spanserver software stack
- Each spanserver is responsible for 100 to 1000 tablets.
- A tablet is a bag of mappings.
- Stored in set of B-tree-like files and write-ahead log.
- Both stored on Colossus.
- Stored in set of B-tree-like files and write-ahead log.
- Mapping: (key:string, timestamp:int64) -> string.
- Thus Spanner is a multi-version k-v store.
The spanserver is organized as:
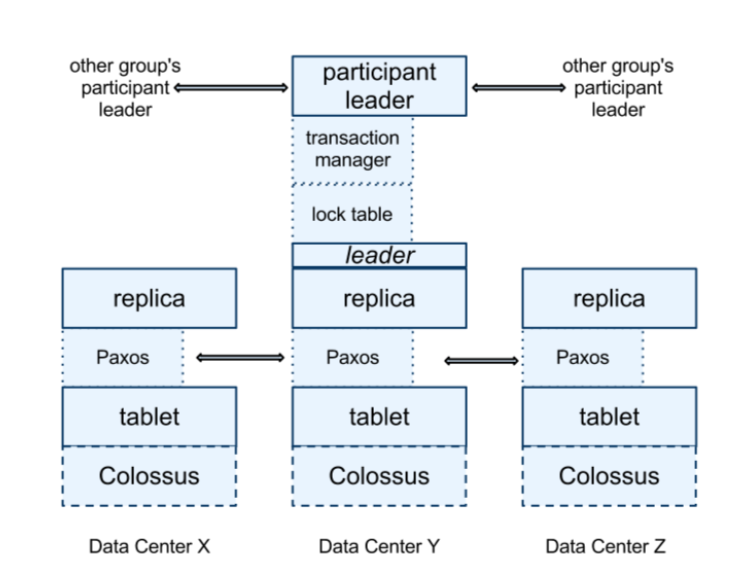
- A single Paxos state machine on top of each tablet.
- Stores its metadata and log in the tablet.
- Supports long-lived leaders with time-based lease (default 10s).
- A set of replicas of a tablet is a Paxos group.
- Writes must initiate Paxos protocol at leader.
- Reads can access any replica.
- At leader replica, spanserver implements a lock table to have concurrency control. (Critical to have long-live leaders)
- Contains state for 2PL: map key range to lock state.
- In contrast, optimistic control will cause bad performance of long-lived transactions in case of conflicts.
- Practice
- Synchronized operations acquire locks.
- e.g., transactional reads.
- Other operations bypass the lock table.
- Synchronized operations acquire locks.
- Contains state for 2PL: map key range to lock state.
Distributed transactions:
- If a transaction involves only one Paxos group (most of them), lock table and Paxos can provide enough transactionality.
- Otherwise, coordination across groups is needed.
- Leader replica spanserver implements a transaction manager. The replica is a participant leader; others are participant slaves.
- Those groups’ leaders coordinate to perform 2PC.
- One group is chosen to be coordinator (with coordinator leader and slaves).
- State of transaction manager is stored in the Paxos group and thus replicated.
Directories and placement
Directory is a bucketing abstraction of a set of contiguous keys that share a common prefix. Applications can use directories to control the locality of the data by choosing the keys carefully.
- A directory is the unit of data placement.
- All data in a directory has the same replication configuration.
- A Paxos group (tablet replicas) can have multiple directories.
- Frequently accessed directories can be local to each other.
- Movedir is used to move directories between Paxos groups; and add or remove replicas to Paxos groups.
- A directory is the unit of specified geographic-replication properties.
- e.g., Specify user group A has 3 replicas in US; group B has 2 replicas in EU.
- Spanner shards a directory into multiple fragments if it grows too large.
- Different fragments may be served from different Paxos groups.
- Movedir moves fragments.
Note: How to ensure locality of a directory if its fragments are in different Paxos groups? My thinking: If those fragments are in different Paxos groups, locality cannot be guaranteed and 2PC is required if a transaction involves multiple fragments. But data in a fragment always stays in the same Paxos group.
Data model
Spanner data features:
- Schematized semi-relational tables, synchronous replication across datacenters.
- Easy to manage, like Megastore.
- Query language
- To support Dremel.
- General-purpose transactions.
- Although 2PC is expensive, Spanner still support cross-row transactions. Application developers is responsible to deal with low-performance problems.
Application data model is layered on top of Spanner’s directory-bucketed k-v mappings.
- An application creates one or more databases in a universe.
- A database can contain unlimited number of schematized tables.
- A database must be partitioned into one or more hierarchies of tables.
- A table looks like relational-database table, with rows, columns and versions.
- A row must have one or more primary-key columns.
- Application can use keys to control data locality.
Example of a database schema:
CREATE TABLE Users {
uid INT64 NOT NULL, email STRING
} PRIMARY KEY (uid), DIRECTORY;
CREATE TABLE Albums {
uid INT64 NOT NULL, aid INT64 NOT NULL,
name STRING
} PRIMARY KEY (uid, aid),
INTERLEAVE IN PARENT Users ON DELETE CASCADE;
DIRECTORYdeclares a top-level directory table in the hierarchy.- A directory is formed with each row in directory table with key K, together with all rows in descendant tables that start with K in lexicographic order.
INTERLEAVE INdeclare descendant tables.ON DELETE CASCADEsays deleting a directory table row will delete all associated rows in descendant tables.- With this directory concept, we can have a user row and its album rows stay together.
TrueTime
API:
| Method | Returns |
|---|---|
TT.now() |
TTinterval: [earliest, latest] |
TT.after(t) |
true if t has definitely passed |
TT.before(t) |
true if t has definited not arrived |
TrueTime uses both GPS and atomic clocks as time references. They have different failure modes; thus can compensate each other.
- Organization:
- TrueTime is implemented by a set of time master machines per datacenter and a timeslave daemon per machine.
- The majority of masters have GPS receivers.
- Advertising uncertainty is typically close to zero.
- The rest of masters use atom clocks. (Armageddon masters)
- Advertising uncertainty slowly increases, derived from conservatively worst-case clock drift.
- Mechanism:
- Masters compare time references against each other.
- Each master cross-checks the divergence rate.
- Every daemons poll a variety of masters (some may be from farther datacenters).
- Apply Marzullo’s algorithm to synchronize local clocks.
Define instantaneous error bound as , which is half of the interval’s width. Average error bound is .
- Before synchronizations, a daemon advertises a slowly increasing time uncertainty .
- is derived from
- conservatively applied worst-case local clock drift
- time-master uncertainty
- communication delay to the time masters.
- is derived from
- is a sawtooth function of time, varying from 1 to 7 ms over each poll interval (30s).
- Applied drift 0 to 6 ms.
- Rate 20 microsec/sec * 30 sec.
- 1 ms is communication delay to the time masters.
- Applied drift 0 to 6 ms.
Concurrency control
TrueTime -> (enables) correctness properties around concurrency control -> features:
- Externally consistent transactions
- Lock-free read-only transactions
- Non-blocking reads in the past.
These features enable a guarantee that a whole-database audit read at a timestamp t will see exactly the effects of every transaction that has committed as of t.
Timestamp management
| Operation | Concurrency control | Replica required |
|---|---|---|
| Read-Write Transaction | pessimistic | leader |
| Read-only transaction | lock-free | leader for timestamp; any for read |
| Snapshot read with client-provided timestamp | lock-free | any |
| Snapshot read with client-provided bound | lock-free | any |
- Read-only transaction
- Must be pre-declared first (not having any write).
- System (leader) chooses a timestamp for it.
- Can then be processed on any replica.
- Incoming writes are not blocked.
- Snapshot read
- Client can specify a timestamp or provide an upper bound and let Spanner to choose one.
- Processed on any replica.
Paxos leader leases
- Spanner’s Paxos use time leases to make leadership long-lived (10 sec by default).
- Lease can be extended when approaching expiration.
- Leader can abdicate by releasing its slaves.
- A leader must wait some time until it can abdicate to preserve the disjointness invariant.
- Within a Paxos group, leaders’ lease intervals should be disjoint. (current leader’s and the subsequent leader’s)
Assigning timestamps to RW transactions
- RW transactions use 2PL.
- Spanner assigns a timestamp at any time when all locks have been acquired, but before any lock has been released.
- The timestamp of the Paxos write representing transaction commit.
- Invariant 1: Within each Paxos group, Spanner assigns timestamps to Paxos writes in monotonically increasing order, even across leaders (current and the subsequent ones within a group).
- Enabled by making use of the disjointness invariant.
- Invariant 2: if the start of a transaction occurs after the commit of a transaction , then the commit timestamp of must be greater than the commit timestamp of .
- Enabled by commit wait.
Serving reads at a timestamp
- Every replica tracks a timestamp value called safe time , to which it’s up to date. A replica can serve a read at a timestamp if .
- is the minimum of:
- : the timestamp of the highest-applied Paxos write.
- For transaction manager, : .
- is the prepared timestamps from a group , inferred from the prepared but not committed transactions (between two phases of 2PC).
Assigning timestamps to RO transactions
- Two steps:
- Assign a timestamp.
- Execute the reads as snapshot reads at this timestamp.
- Spanner usually assigns the oldest timestamp that preserves external consistency.
- A too fresh timestamp like
TT.now().latestmake block if has not advanced sufficiently.
- A too fresh timestamp like
Details
RW transactions
When multiple Paxos groups are involved:
- Writes in a transaction are buffered at the client until commit.
- Therefore, reads in the same transaction don’t see the effects of those writes.
- Reads use wound-wait to avoid deadlocks.
- Client sends keepalive messages to participant leaders when a transaction remains open.
- Client begins 2PC when all reads are completed and all writes are buffered.
- Choose a coordinator group.
- Send a commit message to all participant leaders with the coordinator information and buffered writes.
- Avoid sending data twice (if let the coordinator drive the 2PC).
2PC:
- Non-coordinator-participant leader
- Acquire write locks.
- Choose a prepare timestamp (greater than all assigned).
- Log a prepare record through Paxos.
- Send the prepare timestamp to the coordinator.
- Receive commit timestamp from coordinator.
- Log the transaction’s outcome through Paxos.
- Coordinator
- Acquire write locks.
- Skip prepare phase.
- Hear prepare timestamps from all participant leaders.
- Choose a transaction timestamp s.
- Greater than all prepare timestamps.
- Greater than all assigned at itself.
- Wait until s is definitely passed.
- Concurrent with step 5, log a commit record through Paxos.
- Send the commit timestamp to the client and all participant leaders.
2PC adds an extra network round trip so it usually doubles observed commit latency. It scales well up to 10s of participants, but abort frequency and latency increase significantly with 100s of participants. (This is from F1 paper.)
Read-only transactions
- Spanner requires a scope expression for every read-only transaction.
- Scope: summarize the keys that will be read by the entry transaction.
- To determine the Paxos groups to serve the request.
- Scope: summarize the keys that will be read by the entry transaction.
- Cases:
- If only one Paxos group is involved.
- The leader maintains
LastTS()for the timestamp of the last committed write at this group.- Better than
TT.now().lastest(). - Use it for read timestamp if no prepared transactions.
- Note:
- If prepared transactions exist and deal with the same data as the RO transaction, the RO transaction should be assigned equal to
TT.now().lastest(); then snapshot read will wait until .- When is less than the commit timestamps of those previously prepared transactions. ( advanced.)
- If data to read is unrelated to the prepared transactions, is it safe to use
LastTS()?- Could be, see refinements.
- If prepared transactions exist and deal with the same data as the RO transaction, the RO transaction should be assigned equal to
- Note:
- Better than
- The leader maintains
- Multiple Paxos groups
- Simple option (used by Spanner): use
TT.now().lastest(). - Complicated option: do a round of communication with all groups to negotiate based on their
LastTS().
- Simple option (used by Spanner): use
- If only one Paxos group is involved.
Schema-change transactions
- Spanner supports atomic schema changes.
- Not a standard transaction, since millions of participants could be involved.
- TrueTime is essential for this.
- Bigtable supports atomic schema changes in one datacenter.
- But changes block all operations.
Details:
- The transaction is explicitly assigned a timestamp t in the future.
- Registered in the prepared phase.
- Operations relying on the new schema must wait until t is passed.
Refinements
- Problem of : A single prepared transaction prevents from advancing.
- Even if the read is unrelated to the prepared transaction.
- Refinement: Use a mapping from key ranges to prepared transaction timestamps.
- Can be stored in the lock table.
- Schema change prepared transaction should block all.
- Problem of
LastTS(): A read must be assigned a timestamp after the recent transaction, even if they are irrelevant.- Refinement: Use a mapping from key ranges to commit timestamps.
- Not implemented in 2012.
- Refinement: Use a mapping from key ranges to commit timestamps.
- Problem of : It cannot advance in the absence of Paxos writes.
- A snapshot read at t cannot be executed at Paxos group whose last write happened before t.
- Refinement: Paxos leader advances .
- Set it based on
MinNextTS()within the lease interval. - Enabled by the disjointness of leader lease intervals.
- Set it based on
MinNextTS()is advanced every 8 seconds.- Thus an idle Paxos group may serve reads at timestamp greater than 8 seconds old in the worst case.
- Note: This means a snapshot read may need to wait for 8 seconds to perform the read.
- When .
- Note: This means a snapshot read may need to wait for 8 seconds to perform the read.
- Thus an idle Paxos group may serve reads at timestamp greater than 8 seconds old in the worst case.
Evaluation
Microbenchmarks
- Latency
- For writes, latency stays roughly constant with less std, as number of replicas increases.
- Because Paxos executes in parallel at a group’s replicas.
- For writes, latency stays roughly constant with less std, as number of replicas increases.
- Throughput
- Snapshot reads: increase almost linearly with the number of replicas.
- Because they can be served from any up-to-date replicas.
- RO transactions: increases as number of replicas increases (corresponding number of spanservers also increases).
- Timestamp must be assigned by leader.
- Can then be served by other replicas.
- Write: 1 replica > 5 replicas > 3 replicas.
- Because 1 replica doesn’t need to do replication.
- Number of spanservers increases when 3 replicas -> 5 replicas.
- Also leaders are randomly distributed.
- Snapshot reads: increase almost linearly with the number of replicas.
- 2PC
- 2PC can be scaled up to 100 participants with reasonable latency in the experiment.
Availability
Failure mode:
- Non-leader fail
- No effect on read throughput.
- Leader soft fail (but notify all servers to handoff leadership first)
- Minor effect on read throughput (3% - 4%).
- Leader hard fail
- Severe effect within failed leader lease window.
- Re-elect leader; then catch up in next lease window.
TrueTime
- The 200 us/sec clock drift is a reasonable assumption.
- Bad CPU problem are 6 times more likely than bad clocks.
- Uncertainty comes from:
- Time master uncertainty (generally 0);
- Communication delay to the time masters.
- Experiment shows no significant problem.
- To improve:
- Improve network;
- Reduce causes of TrueTime spikes.
- To improve:
Case study: F1
Painful past:
- Based on MySQL.
- Manual re-sharding was costly and took long time (over two years).
- Data growth was limited by the team.
Reasons choosing Spanner:
- No need to manually re-shard.
- Synchronous replication and automatic failover.
- Transactions.
- e.g., generating secondary indexes.
Practices:
- Choose replica locations to cope with potential outrages and their frontend locations.
- Spanner timestamp makes F1 easy to maintain its in-memory data structures.
- Read a snapshot at a timestamp to construct;
- Then incrementally update.
- A directory typically represents a client.
- Most directories contains only 1 fragment.
- Reads and writes are guarantees to happen on a single server. (Note: a Paxos group?)
- As of 2012, 7 largest directories has 100 to 500 fragments.
- Most directories contains only 1 fragment.
- Large std of write latencies: Caused by a fat tail due to lock conflicts.
- Larger std of read latencies: Because Paxos leaders are spread across two data centers, one of them has SSDs.
Related work
- Megastore
- Consistent replication across datacenters globally.
- Semi-relational data model.
- Similar schema language as Spanner.
- Not high performance.
- On top of Bigtable with high communication costs.
- Not support long-lived leaders.
- Multiple replicas can initiate writes, which can cause unnecessary conflicts in Paxos protocol.
- DynamoDB
- Consistent replication across datacenters within region.
- Provide a key-value interface.
- Database functionality layered on distributed k-v stores.
- But Spanner integrates multiple layers.
- e.g., integrating concurrency control with replication to reduce the cost of commit wait.
- But Spanner integrates multiple layers.
- Scatter
- A DHT-based k-v store layering transactions on top of consistent replication.
- Spanner provides a higher-level interface.
- Walter
- Snapshot isolation within datacenter.
- Calvin, HStroe, Granola
- No external consistency.
- VoltDB
- Not much general replication configurations.
- Farsite
- Bounds of clock uncertainty.
- Much looser than TrueTime’s.
Future work
- Improve monitoring and support tools.
- Tune performance.
- Schema language.
- Automatic maintenance of secondary indices.
- Automatic load-based resharding.
- May support optimistically doing reads in parallel.
- Reduce TrueTime , below 1 ms.
- Better clock crystals.
- Better network.
- Improve local data structure in single node to better support SQL queries.
- Automatically move clients’ application processes between datacenters in response to load changes.
Conclusions
- Combine and extend ideas from two communities:
- Database
- Semi-relational, transactions, SQL query.
- Bigtable misses some database features.
- System
- Scalability, Automatic sharding, fault tolerance, consistency, wide-area distribution.
- Database
- TrueTime
- Enables to build distributed systems with much stronger time semantics.
