
Reference
Abstract
- Distributed storage for managing structured data.
- Scale to petabytes of data across thousands of servers.
- Satisfying different client demands such as data size, latency etc.
1 Introduction
- Goals:
- Wide applicability, scalability, high performance and high availability.
- Simple data model, not a full relational data model.
- Dynamic control over data layout and format.
- Clients can reason about locality properties.
- Indexed using row and column names.
- Data are treated as uninterpreted strings.
- Clients can serialize various data types into them.
- Clients can control whether to serve data out of memory or from disk.
2 Data model
Bigtable is a sparse, distributed, persistent multi-dimensional sorted map, indexed by a row key, column key and a timestamp. The value is an uninterpreted string. (row:string, column:string, time:int64) -> string
A sample piece of data for web page is as follows. Row key is url; column key is content, anchor:cnnsi.com, etc.
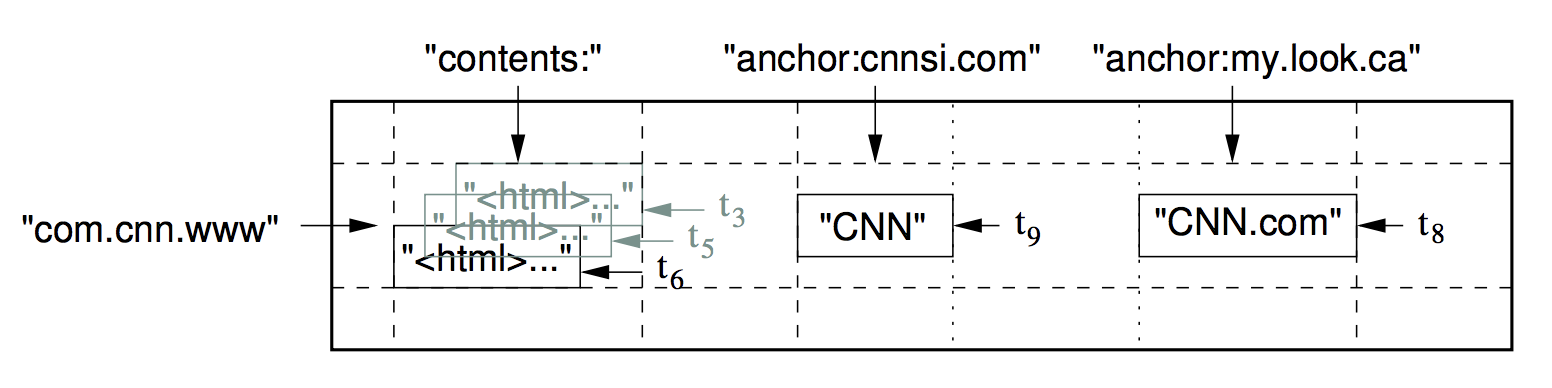
2.1 Row
- Size: up to 64 KB.
- Each read/write under a single row key is atomic.
- No matter how many columns are involved.
- Data are lexicographic ordered by row key.
- Tablet: dynamically partitioned row range.
- Unit of distribution and load balancing.
- Data access can gain good locality.
- i.e., use reversed URL.
2.2 Column families
- Column families: grouped sets of column keys.
- Basic unit of access control: different user can read/write different groups individually.
- Basic unit of disk and memory accounting.
- Data in a family are usually of the same type.
- Number of column families should be small (up to hundreds) and rarely changed during operations.
- Column key:
family:qualifier- In the example of web page data,
anchoris a family.
- In the example of web page data,
2.3 Timestamps
- Represents multiple versions of the same data.
- Can be assigned by Bigtable or clients.
- Decreasing ordered.
- Versions can be garbage collected automatically.
3 API
- Table-related
- Creates/Deletes tables and column families.
- Changes cluster, table and column family metadata, e.g., access control.
- Values
- Writes/Deletes values.
- Looks up values from individual rows.
- Iterates over a subset of data in a table.
- Other
- Single-row transactions.
- e.g., read-modify-write.
- Batching writes across row keys.
- Cells can be used as integer counters.
- Execution of client-supplied scripts.
- Can be used with MapReduce, as inputs/outputs.
- Single-row transactions.
4 Building blocks
- GFS: stores logs and data files.
- Google SSTable is used to store data.
- Persistent, ordered, immutable map from key to values.
- A SSTable contains a sequence of blocks.
- Block indexes are used to locate blocks. (Stored at the end of SSTable)
- Data lookup: Load index into memory -> Find the block by binary search -> Read the block.
- Chubby
- Highly available, persistent distributed lock service.
- Usages for Bigtable:
- Ensure at most one active master.
- Store bootstrap location of data.
- Discover tablet servers and finalize tablet server deaths.
- Store Bigtable schema information.
- Store access control lists.
5 Implementation
3 major components: a library linked into every clients, one master server and many tablet servers.
- Master is responsible for
- assigning tablets to tablet serves;
- detecting addition and deletion of tablet servers;
- load-balancing;
- garbage collection;
- schema changes.
- Tablet server
- managers a set of tablets (10 - ~1000);
- A tablet is a row range in the table, of size 100-200 MB by default.
- handles read and writes operations;
- Clients talk with it directly, not via the master.
- splits tablets.
- managers a set of tablets (10 - ~1000);
Tablet location
3-level hierarchy to store tablet location information. Locations are also cached on client library.
- A Chubby file contains the location of a root tablet.
- Root tablet contains the locations of all tablets in a special
METADATAtable.
- Root tablet is the first tablet of
METADATAtable, but never split.- So no more than 3 levels.
- Root tablet contains the locations of all tablets in a special
METADATAtable- Contains locations of user tablets.
- User tablets
Tablet assignment
Master keeps tracks of:
- the set of live tablet servers
- Uses Chubby exclusive locks.
- If a tablet server is unavailable, the master can detect it and reassign its tablets.
- By trying to acquire its lock.
- current assignment of tablets to tablet servers, including unassigned ones
- Master needs to discover the assignments upon startup.
- scans and communicates with all tablet servers.
- scans
METADATAtable for all tablets.
- Master needs to discover the assignments upon startup.
Master initiates the creation, deletion of table and merging two tablets, thus keeps tracks of these changes regarding tablet assignments. Besides them, tablet split is initialized by tablet server. This change would be known by the master upon change committing or reading the split tablet.
Tablet serving
- A commit log for redo records.
- A memtable for recent updates.
- A sequence of SSTable.
Operations:
- Recover tablet: reads the indices of SSTables into memory and reconstructs the memtable by applying all updates since redo points.
- Writes:
- Write to the commit log.
- Write to the memtable.
- Group commit is good for improving throughput of small mutations.
- Reads: the server reads the merged view of the sequence of SSTables and memtable.
Compactions
- Minor compaction
- Write the reach-threshold memtable into SSTable.
- Reduce memory usage.
- Reduce amount of data to read during recovery.
- Write the reach-threshold memtable into SSTable.
- Merging compaction
- Merge a few SSTables and memtable into a new SSTable.
- Major compaction
- Merge all SSTables into a new SSTable.
- Remove all deletion entries(tombstone) in old SSTables.
- Tombstone of a record in a newer SSTable prevent the use of the record in a older SSTable.
Refinements
- Locality groups
- Groups multiple column families to use a separate SSTable, in a tablet.
- Accessed together frequently.
- Can be declared to be in-memory.
- Groups multiple column families to use a separate SSTable, in a tablet.
- Compression
- Can specify whether to compress and compression format for locality groups.
- Example compression format: 1st pass using Bently & McIlroy’s scheme; 2nd pass with a fast compression algorithm.
- Often 10-to-1 reduction in space.
- Caching for read performance
- Scan cache: higher-level caching the k-v pairs returned by the SSTable interface.
- Block cache: lower-level caching the SSTable blocks that were read from GFS.
- Bloom filters
- Whether a SSTable might contain any data for a specified row/column pair.
- Commit-log implementation
- Appends mutations to a single commit log per tablet server, for all tablets.
- Avoids a large number of log file being written concurrently to GFS.
- Recovery becomes complicated since tablets will be moved to many other tablet servers.
- Master will initialize a sort of the log entries with respect with keys to tackle this.
- Tablet server will maintain two log writing threads. If one thread performs poorly, switches to the other one.
- Appends mutations to a single commit log per tablet server, for all tablets.
- Speeding up tablet recovery
- The source tablet server with do minor compaction on tablets and the log to speed up.
- Exploiting immutability
- All generated SSTables are immutable.
- To delete data, use garbage collection on obsolete SSTable data.
- Can split the tablet quickly. Child tablets share the SSTable of the parent tablet.
- Memtables are mutable; we use copy-on-write to reduce contentions during reads and reads and writes can be proceeded in parallel.
- All generated SSTables are immutable.
Performance evaluation
- Performance doesn’t increase linearly with respect to the number of servers.
- There is a significant drop in per-server throughput.
- Imbalance in load in multiple server configurations.
- Network links are saturated.
- There is a significant drop in per-server throughput.
Lessons
- Systems are vulnerable to many types of failures, expected or unexpected.
- Add new features until it’s clear how they would be used.
- Proper system-level monitoring.
- Value of simple design.
