
Introduction
- Transformer, an encoder and decoder model, solely based on attention mechanisms.
- Not using recurrence and convolutions, more parallelizable, capturing long-distance context in . Therefore, it requires less time to train.
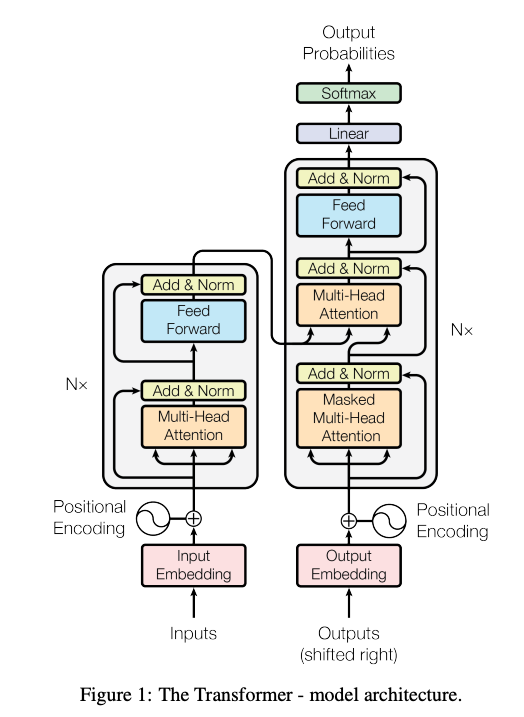
- One layer contains two sub-layers: attention and Feed Forward (FFN).
- Employ a residual connection around each of the two sub-layers, then layer normalization.
- The output of each sub-layer is
- Multiple layers. e.g., Llama-3-8B has 32 layers.
Input preparation
- Input is a natural language sequence with tokens.
- Input is first converted to a matrix of dimension . is the dimension of token embedding vector. e.g., 768, 4096.
- Add positional embeddings to the input matrix to provide position info for each token. The dimension doesn’t change.
- Using fixed sinusoid function. Can also use learned ones.
Self-attention
While processing a sequence, automatically learn the contexts, relations between different parts.
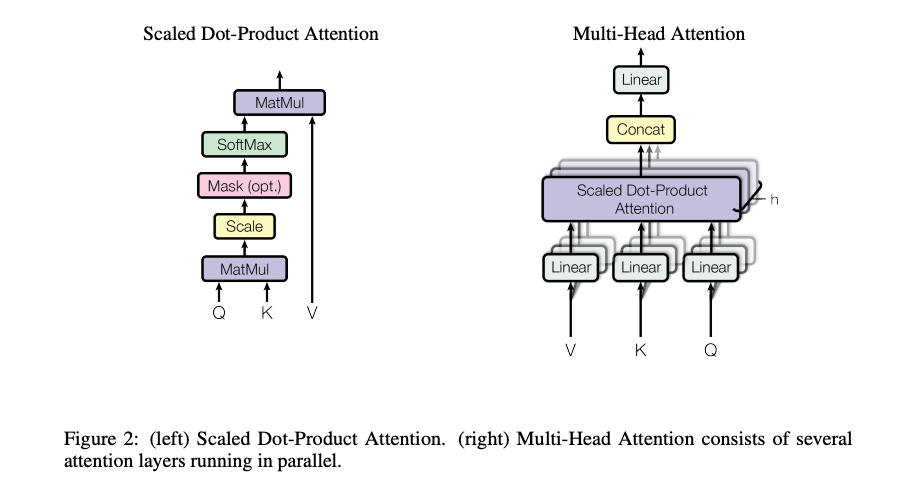
Calculate (Query), (Key), (Value) using the input matrix and projection matrices .
- , the query, for each position, what context it wants to search for
- is of dimension . is of dimension .
- , the key, for each position, what info it can provide for the search, like a search index
- is of dimension . is of dimension .
- $V = X W^V$$, the value, for each position, if selected, what detailed info it can provide, like the payload
- is of dimension . is of dimension .
With training, and learn about searching and matching contexts. learns about information providing.
\[\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V\]
- is calculating similarity between query and all keys.
- is for scaling to prevent gradient vanishing.
- Softmax is for normalizing similarity scores to probabilities, the total is 1.
- gets the final value. Values with higher similarities occupy larger portion in the final value. The dimension is .
Multi-head attention
Learn the same sequence from multiple aspects. Multi-head attention allows the model to learn these aspects independently, in parallel. There could be shallow heads focusing on local info, deep heads for global info.
- Linear projection for heads: project the initial for each head with .
- The dimension is usually split equally across heads. . So the dimension of is . So multi-head won’t increase computation cost.
- Parallel attention:
- The dimension is .
- Concatenation: Concatenate the outputs of all heads. The dimension is .
- Final linear: use a to project the output back to the original dimension, also synchronize info from all heads.
- Diversity: learns in various aspects.
- Robustness: If one head fails due to noise, other heads are still working.
- Sub-space learning: Easier to capture complex info by learning in multiple lower-dimensional spaces.
Feed Forward network (FFN)
FFN is after the attention layer. It’s position/point-wise, each position only cares about itself, learning deeper information. This layer adds nonlinear to the overall model.
\[\text{FFN}\left(x\right) = \text{activation}\left(xW_1+b_1\right)W_2+b_2\]
- Dimension expansion
- Using of dimension to expand the input dimension to
- is usually larger (~4X) than . It’s easier to identify and extract complex details in higher-dimensional spaces.
- Dimension reduction
- Use of dimension to reduce to the original dimension.
- Filter noise and compress useful info.
- The activation function is nonlinear, e.g., ReLU, .
- Token has gained context info from attention layer; FFN is for further digesting these info.
- Dimension expansion:
- Store knowledge and memories in FFN weight matrices.
- ~2/3 weights in a LLM are in FFN.
Training
- Adam optimizer
- Regularization
- Residual dropout on (1) the output of each sub-layer and (2) the addition of input embedding and positional embedding.
- Label smoothing
